

Imagine um mundo onde as respostas não são apenas “sim” ou “não”. Neste universo, tudo existe em gradações, como a temperatura morna ou a altura mediana. É nesse contexto que a lógica nebulosa se destaca. Porém, para compreendê-la, precisamos primeiro revisitar a teoria das probabilidades e a teoria dos conjuntos. Elas formam a base do nosso raciocínio em situações de incerteza e imprecisão. A seguir, vamos desvendar esses conceitos passo a passo.
A Base do Raciocínio: Probabilidades e Lógica
A teoria das probabilidades é o ramo da matemática que quantifica a chance de um evento ocorrer. Começamos com proposições, que são afirmações sobre o mundo. Uma proposição simples é direta, como “hoje vai chover”. Já uma proposição composta combina duas ou mais ideias. Para conectá-las, usamos operadores lógicos. O conectivo E (conjunção) exige que todas as condições sejam verdadeiras. O OU (disjunção) requer que pelo menos uma o seja. O SE ENTÃO (implicação) estabelece uma relação de causa e condição, enquanto o SE SOMENTE SE (bi-implicação) exige uma dependência dupla.
Trabalhamos frequentemente com a incerteza, pois não temos controle sobre todas as variáveis. A probabilidade incondicional (ou a priori) é a chance de um evento sem considerar qualquer informação externa. Por outro lado, a probabilidade condicional mede a chance de um evento acontecer, dado que outro já ocorreu. Para analisar cenários, utilizamos variáveis aleatórias. Uma variável aleatória discreta assume valores contáveis (como o número de carros em um estacionamento). Já uma variável contínua pode assumir qualquer valor em um intervalo (como a temperatura de uma sala). Quando dois eventos não se influenciam, dizemos que são independentes.
Dois teoremas são fundamentais aqui. A regra do produto calcula a probabilidade da ocorrência simultânea de dois eventos. Já o teorema de Bayes é um poderoso instrumento para revisar crenças. Ele atualiza a probabilidade de uma hipótese à medida que novas evidências são apresentadas. Entretanto, a probabilidade tradicional lida com a frequência de eventos. A lógica nebulosa, que veremos a seguir, lida com o significado impreciso dos conceitos.
A Estrutura dos Conjuntos: Do Clássico ao Nebuloso
Na matemática clássica, um conjunto é uma coleção bem definida de objetos. O conjunto universo é a totalidade dos elementos em um dado contexto. Com os conjuntos tradicionais (ou crisp), um elemento pertence ou não pertence a ele. Não há meio-termo. As operações básicas são: união (elementos que estão em pelo menos um dos conjuntos), interseção (elementos que estão em ambos), complemento (elementos que não estão no conjunto), e diferença (elementos de um conjunto que não estão no outro). As relações de pertence, não pertence, contém e não contém são binárias e absolutas.
Essa lógica binária é eficiente para computadores, mas falha ao representar o pensamento humano. Como classificar a temperatura “agradável”? É aí que entram os conjuntos nebulosos (ou fuzzy sets). Neles, a transição entre “pertencer” e “não pertencer” é gradual. Cada elemento possui um grau de inclusão, representado por um número entre 0 e 1. Para definir esses graus, usamos funções de inclusão. As mais comuns são as funções triangulares e trapezoidais. Imagine um gráfico: o topo do triângulo ou do trapézio representa o grau máximo (1) de inclusão naquele conjunto (por exemplo, temperatura “morna”). As bordas representam a transição suave para os conjuntos vizinhos (“fria” ou “quente”).
O Motor da Decisão: O Sistema Nebuloso
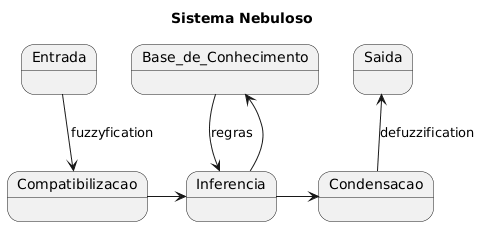
Um sistema nebuloso é uma estrutura que mapeia entradas precisas em saídas precisas, usando os princípios da lógica nebulosa. Ele é composto por quatro módulos principais, conforme ilustrado no diagrama. O processo se inicia com a Entrada, um valor numérico e exato do mundo real, como 23°C.
1. Fuzzyficação (Compatibilização): Este módulo recebe a entrada precisa e a converte em graus de pertinência para os conjuntos nebulosos. O valor 23°C pode ser 0,2 “frio”, 0,8 “morno” e 0,0 “quente”. A incerteza sobre o que é “morno” é transformada em um valor matemático.
2. Inferência: Agora, o sistema aplica as regras. A Base de Conhecimento contém regras no formato “SE (condição nebulosa) ENTÃO (ação nebulosa)”, como “SE temperatura é morna ENTÃO ventilador é lento”. A inferência avalia o “SE” (usando operadores como o E e OU nebulosos) e aplica o resultado ao “ENTÃO”. A Avaliação, Agregação, Implicação e Combinação são etapas internas que processam todas as regras ativas para gerar um conjunto nebuloso resultante.
3. Condensação (Defuzzificação): O resultado da inferência é um conjunto nebuloso. Contudo, para agir no mundo real (como girar um motor), precisamos de um valor preciso. A condensação converte esse conjunto nebuloso em um número nítido, calculando, por exemplo, o centro de gravidade da figura formada. Esse valor é, então, enviado para a Saída, controlando a velocidade do ventilador.
Portanto, a lógica nebulosa nos permite programar máquinas para pensar de forma mais humana, lidando com a imprecisão da linguagem e tomando decisões suaves e adaptativas em um mundo de infinitas gradações.
