

Você já parou para pensar como empresas como Netflix sabem exatamente qual filme recomendar, ou como o mercado ajusta os preços dos produtos em tempo real? A resposta para essas perguntas está em um processo fascinante chamado Business Intelligence (BI), ou Inteligência de Negócio. Para quem está começando, o BI pode parecer um conceito abstrato e complexo, repleto de jargões tecnológicos. No entanto, podemos visualizá-lo de forma muito clara como uma escada, onde cada degrau representa um estágio de evolução: partimos do caos dos dados crus e chegamos ao topo, que é a sabedoria para tomar a melhor decisão.
Para ilustrar essa jornada de forma didática, utilizaremos um diagrama de fluxo simples (semelhante a uma UML). Dessa maneira, detalharemos as etapas fundamentais para que a informação se transforme em ação. Vamos percorrer, passo a passo, esse caminho, entendendo o que acontece em cada fase e onde entram em cena ferramentas poderosas como a Estatística, a Classificação de dados e o Aprendizado de Máquina (Machine Learning).
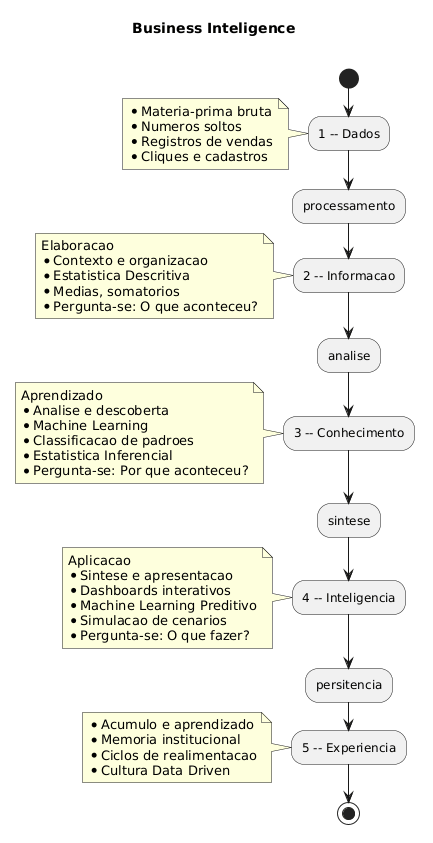
1 – A Matéria-Prima – Os Dados
A jornada começa com os dados advindos das operações transacionais das operações da empresa. Em outras palavras, pense nos dados como a matéria-prima bruta, o petróleo antes de refiná-lo. São números soltos, textos, registros de vendas, cliques em um site, datas, cadastros de clientes. Sozinhos, eles não contam uma história e podem até confundir. Por exemplo, saber que “vendemos 150 unidades” é apenas um dado. Ele representa o alicerce de tudo, mas ainda não oferece significado prático para o gestor.
2 – O Refinamento – A Informação
O próximo degrau é a Informação. Aqui, aplicamos o primeiro filtro: o processamento. Nós organizamos os dados, limpamos (removendo duplicatas ou erros) e os contextualizamos. Além disso, a Estatística Descritiva entra em ação nessa fase. Utilizamos médias, medianas, somatórios e porcentagens para dar sentido ao caos inicial.
Agora, aquele dado “150 unidades” ganha um contexto mais rico: “Vendemos 150 unidades do Produto X na região Sul durante o mês de janeiro.” Portanto, já temos uma informação clara e objetiva. Ela responde à pergunta “O que aconteceu?”.
3 – A Descoberta – O Conhecimento
Com a informação em mãos, subimos para o estágio do Conhecimento. Este constitui o coração da análise. Aqui não basta saber o que aconteceu; precisamos entender por que isso aconteceu. Trata-se da fase da análise e elaboração de hipóteses.
É neste degrau que a estatística se aprofunda, deixando de ser apenas descritiva para se tornar inferencial. Além disso, o Aprendizado de Máquina (Machine Learning) começa a brilhar. Utilizamos técnicas para encontrar padrões, correlações e tendências que o olho humano não conseguiria perceber sozinho.
Aplicamos aqui a Classificação. Por exemplo, o sistema pode classificar um cliente como “propenso a comprar” ou “propenso a cancelar” com base no histórico de informações. Do mesmo modo, usamos Machine Learning para responder: “Que fatores levaram ao aumento das vendas em janeiro?” ou “Qual é a tendência de vendas para o próximo mês?”. Em suma, o conhecimento responde à pergunta “Por que isso aconteceu?”.
![PlantUML Syntax:</p>
<p>@startuml</p>
<p>skinparam componentStyle uml2</p>
<p>title Capacidade relacionadas ao ambiente Business Inteligence</p>
<p>package “Dados Externos” {<br />
component [Planilhas] as Externos<br />
}</p>
<p>package “Dados Internos” {<br />
component [Planilhas] as Internos<br />
}</p>
<p>cloud Internet as I{<br />
}</p>
<p>cloud Intranet as R{<br />
}</p>
<p>database “Data Mining” {<br />
[Predicao] as PRED<br />
[Correlacao] as C</p>
<p>}</p>
<p>cloud Descoberta as D{<br />
}</p>
<p>database “Data Warehouse” {<br />
[Historico] as H<br />
[Analitico] as AN</p>
<p>}</p>
<p>Internos -down-> R</p>
<p>Externos -down-> I</p>
<p>R -down->PRED<br />
I -down->PRED<br />
PRED -down->C<br />
C-down->D<br />
D-down->H</p>
<p>H -down-> AN</p>
<p>@enduml</p>
<p>](http://www.plantuml.com/plantuml/img/XPBBQiCm44NtynL3zjdq0qfIE-0iMeoxwC9qCP66H4JM18rCMqB_lR9hkmyAtPYh8zqpjZ1iD55CVUT1povSA5A7HhgB10xfCRrvnhnv0ycb70kwa76MB6DadwC4igH8WjGTNAumtlNg0glYFg-yEt8m3BbsfYFZgYGhYhlNn368hl0AopHiQq_1-HFfCzBN8NZ_NH_C_zRdGxbklFHs0fp6pUjt76d2pO0j9JgGZjCIuRqBBXo7KMqTsJf3ClhhPbT2MqWSRsA2nQ8jMOqSE6P3vkKVuYUAV99UUNHNJfD4Ppuz5RJRGDwb6MmVic3-95nRUGdhMsnWlgG5xQ6Py_Y6-n-huJ630eefbL1EgO9gCUMH6mvs-3S-0000)
4 – A Visão Estratégica – A Inteligência
Se o conhecimento representa o entendimento, a Inteligência representa a capacidade de agir com base nesse entendimento. Esta fase envolve a síntese e a apresentação. Ou seja, constitui a materialização do BI propriamente dito. Toda a análise realizada anteriormente se sintetiza em dashboards interativos, relatórios dinâmicos e scorecards.
Aqui, o Aprendizado de Máquina se utiliza de forma mais preditiva e prescritiva. Algoritmos avançados podem simular cenários e sugerir a melhor ação. Por exemplo, a inteligência pode indicar: “Para aumentar as vendas, devemos focar no Produto X e oferecer um desconto de 10% para clientes da região Sul, pois a análise mostra que esse perfil responde bem a esse estímulo.” Assim, a inteligência responde à pergunta “O que fazer?”.
5 – O Acúmulo – A Experiência
A Experiência surge quando aplicamos a inteligência repetidamente. Cada ciclo de decisão gera um novo resultado, que realimenta o sistema. Consequentemente, a empresa aprende com os acertos e erros. A persistência e a aplicação contínua da inteligência criam uma memória institucional. Com o tempo, a organização não apenas reage ao mercado, mas antecipa movimentos, pois acumulou know-how. Ela representa o “saber fazer” que se transforma em cultura.
6 – O Objetivo Final – A Tomada de Decisão
Finalmente, chegamos ao topo da escada: a Tomada de Decisão para o Negócio. Este constitui o objetivo final de todo o processo de Business Intelligence. Todo o caminho percorrido, da coleta do dado, à geração de experiência; existe unicamente para dar suporte a uma única ação: decidir. A decisão pode envolver lançar um novo produto, cortar custos, entrar em um novo mercado ou até demitir um funcionário.
Quando a decisão se baseia em um processo sólido de BI, ela deixa de representar um “chute” ou uma intuição vaga e se torna uma decisão orientada por dados (Data Driven). O gestor não aposta; ele age com a convicção de quem possui a informação tratada, o conhecimento analisado e a inteligência aplicada a seu favor.
Conclusão
Portanto, o Business Intelligence representa muito mais do que um software ou um departamento de TI. Ele constitui uma filosofia de gestão que transforma a empresa em um organismo vivo e inteligente. Começando pelos dados brutos e passando pelos filtros da estatística, classificação e aprendizado de máquina, as organizações conseguem não apenas enxergar o passado, mas entender o presente e planejar o futuro com muito mais segurança. Por fim, para o iniciante, a principal lição permanece: dados constituem o recurso, mas a verdadeira inteligência reside na capacidade de interpretá-los e agir com base neles.
