
O que é uma Busca?
Primeiramente, uma busca é o processo de percorrer um grafo para visitar cada vértice em uma ordem definida. Em essência, ela descobre nós não visitados durante essa travessia sistemática. Contudo, o ato de visitar pode incluir leitura ou atualização do vértice. Cada vértice é designado como descoberto ou processado após a busca. Além disso, a ordem de visitação determina a estratégia empregada. Grafos representam estados que simulam um espaço físico ou abstrato. Por exemplo, um grafo pode incluir direcionalidade entre suas conexões. Igualmente, um peso pode ser atribuído a uma aresta específica. Esse peso define distância, tempo ou outra métrica relevante. A informação do peso é usada para otimizar caminhos. Portanto, a busca explora essas conexões ponderadas sistematicamente.
Busca não informada (cega)
Na abordagem não informada, a IA não recebe dados além da estrutura do grafo. Assim, ela explora o espaço de estados sem pistas externas. Apenas a topologia do grafo é considerada durante a navegação. Por conseguinte, algoritmos clássicos como BFS e DFS se enquadram aqui. A busca em largura (BFS) visita todos os vizinhos antes de aprofundar. Já a busca em profundidade (DFS) avança até o fim de cada ramo. Ambas não usam heurísticas para guiar suas decisões. Todavia, elas garantem completude em grafos finitos.
Busca informada (heurística)
Por outro lado, a busca informada emprega heurísticas para acelerar a solução. Heurística é uma suposição bem fundamentada sobre o caminho ideal. Por exemplo, ela aponta uma direção sem dar instruções exatas. Essa direção é sugerida com base em conhecimento prévio do problema. Analogamente, estar perdido em uma cidade é uma boa metáfora. As pessoas indicam o rumo do hotel, mas sem detalhes precisos. Às vezes, apenas informam a distância aproximada até o destino. Desse modo, a heurística reduz o número de nós avaliados. Entretanto, ela não garante a solução ótima em todos os casos.
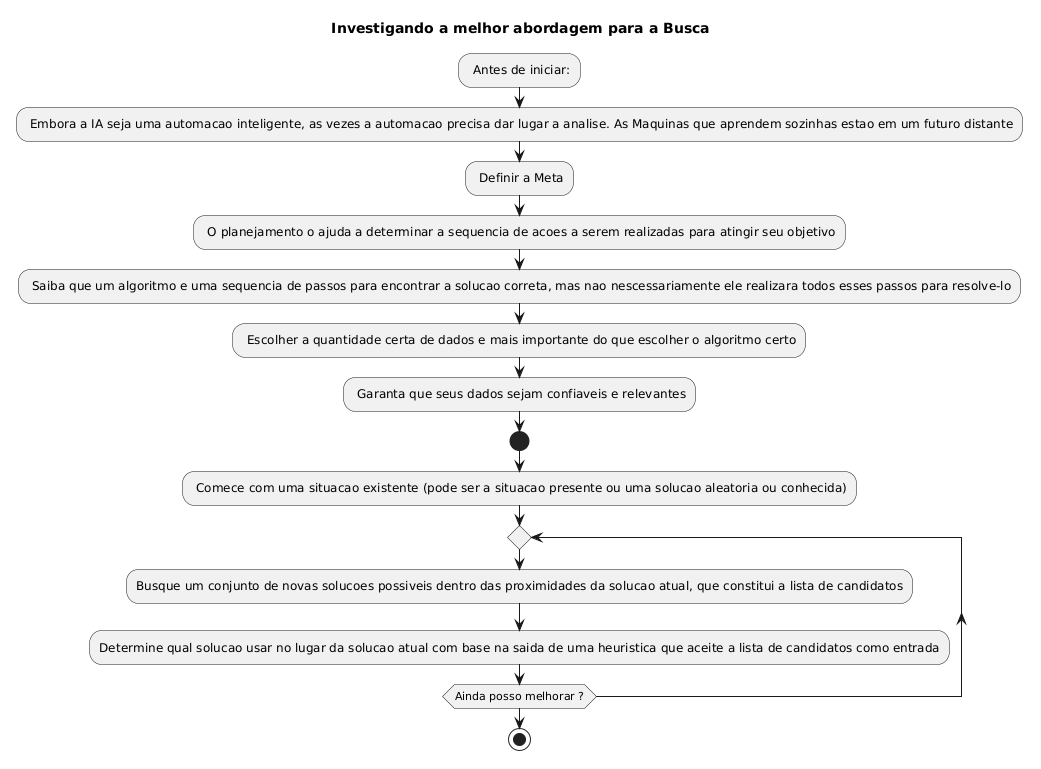
Busca local e otimização
Ademais, a busca local é uma estratégia poderosa para problemas complexos. Ela começa a partir de uma solução atual ou imperfeita. Depois, move-se um passo por vez para soluções vizinhas. A viabilidade de cada vizinho é avaliada iterativamente pelo algoritmo. Assim, ela escapa de complexidades exponenciais típicas de problemas NP. Por exemplo, a busca local melhora a solução até um ponto ótimo local. Contudo, pode ficar presa em máximos ou mínimos locais. Para evitar isso, usam-se técnicas como recozimento simulado ou tabu. Finalmente, a busca local combina heurística astuta com restrições práticas. Essas restrições limitam o número inicial de avaliações possíveis. Em resumo, a busca em grafos é o coração da IA funcional. Ela representa oportunidades futuras a partir do estado atual. Seja cega ou informada, cada estratégia tem seu uso adequado. A escolha do método é determinada pelo contexto e pelos recursos disponíveis. Além disso, a busca local oferece soluções viáveis para problemas reais. Por fim, compreender esses conceitos permite projetar agentes inteligentes mais eficientes. A otimização contínua, passo a passo, refina soluções imperfeitas. Dessa forma, a busca não é apenas um algoritmo – é uma filosofia de exploração.
Navegando no Labirinto: Como a IA Escolhe o Melhor Caminho?
Agora, vamos dar um passo adiante. Se a busca é a arte de explorar um labirinto, precisamos entender quais estratégias a IA pode usar para não se perder. É sobre isso que falaremos hoje: os diferentes métodos de busca, desde os mais simples e “cegos” até os mais sofisticados que utilizam “intuição” (heurísticas) e até mesmo enfrentam adversários.
Mapeando o Problema: Representação de Estados e Operadores
Antes de qualquer algoritmo, precisamos responder a uma pergunta crucial: “O que estamos procurando e como podemos mudar o cenário atual?”.
- Estados: Cada estado é uma fotografia do problema em um determinado momento. Uma boa representação captura apenas as informações essenciais, ignorando detalhes irrelevantes. Por exemplo, no problema clássico das jarras d’água, a quantidade de água em cada jarra define o estado.
- Operadores: São as ações que transformam um estado em outro. “Encher a jarra”, “esvaziar” ou “transferir água” são operadores que criam novos estados na nossa árvore de busca.
Busca Cega: Explorando sem um Mapa
Quando a IA não possui nenhuma informação extra sobre o problema, ela utiliza a Busca Cega (ou Não-Informada). Imagine estar em um labirinto sem saber onde fica a saída; você só pode explorar corredores metodicamente. As principais estratégias são:
- Busca em Largura (BFS): Explora todos os estados de um nível antes de avançar para o próximo. É garantido que encontrará a solução mais curta, mas pode consumir muita memória.
- Busca em Profundidade (DFS): Avança até o fim de um caminho antes de retroceder. É econômica em memória, mas pode se perder em caminhos infinitos e não garante a solução mais curta.
- Busca de Custo Uniforme (UCS): Leva em conta que ações podem ter custos diferentes. Ela sempre expande o caminho com o menor custo acumulado, garantindo a solução de menor custo total.
Busca Heurística: A Inteligência para Acelerar a Solução
Em problemas maiores, como encontrar a rota mais rápida em um GPS, a busca cega se torna inviável. É aqui que entra a Busca Heurística (ou Informada). Uma heurística funciona como um “palpite fundamentado” sobre qual caminho é mais promissor.
Em vez de explorar todas as opções, a IA “aposta” em caminhos que parecem levar mais rapidamente ao objetivo, como a distância em linha reta até o destino final. Os dois principais algoritmos são:
- Gulosa – Best-First Search: Expande o estado que parece estar mais próximo do objetivo, guiado exclusivamente pela heurística.
- Algoritmo A Estrela (A*): Considera tanto o custo já percorrido quanto a estimativa heurística. Ele combina o melhor do mundo real (custo) com o melhor da intuição (heurística) para encontrar o caminho mais eficiente.
Busca com Adversários: Quando Você Tem um Oponente
E quando o problema envolve um adversário que também quer vencer? É o caso dos jogos de tabuleiro, como xadrez ou jogo da velha. A IA precisa planejar seus movimentos antecipando as jogadas do oponente. É o reino da Busca com Adversários.
- Algoritmo Minimax: A IA assume que ambos os jogadores jogarão de forma otimizada. O agente principal (maximizador) busca maximizar seu resultado, enquanto o adversário (minimizador) tenta minimizá-lo. O algoritmo constrói uma árvore de jogo e propaga os valores das jogadas, escolhendo a que oferece a melhor garantia.
- Poda Alfa-Beta: Esta é uma otimização inteligente para o Minimax. Ela “poda” (corta) ramos da árvore de busca que são irrelevantes, pois não afetarão a decisão final. Imagine que você já encontrou uma jogada que garante uma boa vantagem; a IA não precisa analisar detalhadamente outras jogadas que são claramente piores. Isso acelera a tomada de decisão sem comprometer a qualidade.
Conclusão
A busca, em Inteligência Artificial, vai muito além de simplesmente percorrer caminhos. Ela envolve uma jornada por um “espaço de estados” bem definido, utilizando desde métodos sistemáticos e seguros (cegos) até estratégias inteligentes que usam heurísticas para encontrar atalhos.
Quando um adversário entra em cena, algoritmos como o Minimax e a Poda Alfa-Beta permitem que a IA pense no futuro, antecipando movimentos para garantir a vitória. Dominar esses conceitos é essencial para quem deseja projetar agentes inteligentes e eficientes, seja para jogar xadrez, otimizar rotas de entrega ou solucionar problemas complexos do mundo real.
— Artigo complementar ao post “Entendendo o que é uma Busca”
