
O que é um Histograma?
Um histograma é uma representação gráfica de distribuição de dados numéricos contínuos.
É similar a um gráfico de barras, mas agrupa os dados em intervalos (chamados de “bins” ou “classes”) e mostra a frequência de observações em cada intervalo.
O histograma é muito importante no estudo de variáveis quantitativas principalmente para variáveis contínuas, com ele podemos saber como as variáveis estão distribuídas
Por meio do histograma conseguimos calcular os quantis
Primeiro precisamos definir o número de intervalos a serem considerados, para este caso consideraremos 6 intervalos.
Vamos obter nos dados o valor mínimo e máximo.
amplitude do intervalo = (valor máximo – valor mínimo) ÷ 6
limite inferior = valor mínimo
limite superior = valor máximo
densidade da frequência = frequência relativa ÷ amplitude do intervalo
Abaixo vamos calcular no R e obter a tabela de frequência e histogramas com frequência absoluta e densidade de frequência .
Vamos obter nos dados o valor mínimo e máximo.
amplitude do intervalo = (valor máximo – valor mínimo) ÷ 6
limite inferior = valor mínimo
limite superior = valor máximo
densidade da frequência = frequência relativa ÷ amplitude do intervalo
Abaixo vamos calcular no R e obter a tabela de frequência e histogramas com frequência absoluta e densidade de frequência .
Exemplo prático em R
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 |
# Linguagem : R #======================================== # CRIAR DIRETÓRIO PARA SALVAR #======================================== # Definir o diretório de destino diretorio <- "C:/graficos" # Criar o diretório se não existir if (!dir.exists(diretorio)) { dir.create(diretorio, recursive = TRUE) cat("\nDiretório criado:", diretorio, "\n") } x <- c(27772, 19014, 14286, 11651, 12911, 7464, 7000, 6418, 4571,5891,5012, 6207, 7893, 6947, 7536, 10129) cat("valor mínimo = ",min(x)) cat("valor máximo = ",max(x)) cat("tamanho do intervalo = (", max(x), " - ", min(x), ") ÷ 6 = ", (max(x) - min(x))/6, "Km2") aux = min(x) + (max(x) - min(x)) * (0:6)/6 #======================================== # TABELA DE FREQUÊNCIAS (COM FORMATAÇÃO BRASILEIRA) #======================================== # Criar breaks arredondados aux_rounded <- round(aux, 1) # Criar intervalos formatados no estilo brasileiro intervalos <- character() for(i in 1:(length(aux_rounded)-1)) { inicio <- format(aux_rounded[i], nsmall = 1, big.mark = ".", decimal.mark = ",") fim <- format(aux_rounded[i+1], nsmall = 1, big.mark = ".", decimal.mark = ",") intervalos[i] <- paste0("de ", inicio, " a ", fim) } # Contar frequências manualmente frequencias <- numeric() for(i in 1:(length(aux_rounded)-1)) { if(i == 1) { frequencias[i] <- sum(x >= aux_rounded[i] & x <= aux_rounded[i+1]) } else { frequencias[i] <- sum(x > aux_rounded[i] & x <= aux_rounded[i+1]) } } # Criar dataframe manualmente freq_df <- data.frame( `CLASSE (KM²)` = intervalos, `FREQUÊNCIA ABSOLUTA` = frequencias, `FREQUÊNCIA RELATIVA` = paste0(round(frequencias / length(x) * 100, 2), "%"), check.names = FALSE ) # Imprimir a tabela de frequências cat("\n=== TABELA DE FREQUÊNCIAS ===\n") print(freq_df, row.names = FALSE) #======================================== # SALVAR TABELA COMO IMAGEM PNG #======================================== if(!require(gridExtra)) install.packages("gridExtra") if(!require(ggplot2)) install.packages("ggplot2") library(gridExtra) library(ggplot2) # Salvar a tabela como PNG png("C:/graficos/tabela_frequencia.png", width = 1200, height = 400, res = 100) # Criar tabela formatada grid.table(freq_df, rows = NULL, theme = ttheme_minimal( base_size = 10, padding = unit(c(4, 4), "mm"), core = list( bg_params = list(fill = c("#F7F7F7", "#FFFFFF"), col = "black"), fg_params = list(hjust = 0, x = 0.03) ), colhead = list( bg_params = list(fill = "#0E4C3E", col = "black"), ffg_params = list(col = "white", fontface = "bold") ) )) dev.off() cat("Tabela de frequência salva como: C:/graficos/tabela_frequencia.png\n") #======================================== # HISTOGRAMA 1 (Frequência Absoluta) #======================================== # x = Os dados numéricos para construir o histograma # breaks = Define os intervalos (bins) do histograma # right = Controla como os intervalos são fechados se # TRUE: Intervalos são fechados à direita (a, b] # FALSE: Intervalos são fechados à esquerda [a, b) # ylab = Rótulo do eixo Y (vertical) # main = Título principal do gráfico # xlab = Rótulo do eixo X (horizontal) # col = Cor das barras do histograma # ylim = Limites do eixo Y (de 0 a 12) # axes = Suprime a criação automática dos eixos # xlim = Limites do eixo X (de 0 a 30.000 km²) # Salvar o histograma 1 como PNG png(file.path(diretorio, "histograma1_frequencia_absoluta.png"), width = 800, height = 600) d = hist(x, breaks = aux, right = T, ylab = "FREQUÊNCIA ABSOLUTA", main = "DESMATAMENTO EM KM2", xlab = "KM2", col="#0E4C3E", ylim = c(0,12), axes = F, xlim = c(0,30000)) axis(1, c(0,aux),round(c(0,aux),1)) axis(2) text(d$mids, d$counts+0.5, paste(round(d$density*(max(x) - min(x))/6*100,2),"%", sep="")) dev.off() # Fechar o dispositivo gráfico cat("Histograma 1 salvo como: histograma1_frequencia_absoluta.png\n") #======================================== # HISTOGRAMA 2 (Densidade de Frequência) #======================================== # Salvar o histograma 2 como PNG png(file.path(diretorio, "histograma2_densidade_frequencia.png"), width = 800, height = 600) d = hist(x, breaks=aux, right=T, prob=T, ylab="DENSIDADE DE FREQUÊNCIA", main="DESMATAMENTO EM KM2", xlab="KM2", col="#0E4C3E", ylim=c(0,0.0002), axes=F, xlim=c(0,30000)) axis(1, c(0,aux), round(c(0,aux),1)) axis(2) text(d$mids, d$density+0.5e-5, paste(round(d$density*(max(x) - min(x))/6*100,2),"%", sep="")) dev.off() # Fechar o dispositivo gráfico cat("Histograma 2 salvo como: histograma2_densidade_frequencia.png\n") #======================================== # MOSTRAR HISTOGRAMAS NA TELA TAMBÉM #======================================== # Mostrar o histograma 1 na tela d = hist(x, breaks = aux, right = T, ylab = "FREQUÊNCIA ABSOLUTA", main = "DESMATAMENTO EM KM2", xlab = "KM2", col="#0E4C3E", ylim = c(0,12), axes = F, xlim = c(0,30000)) axis(1, c(0,aux),round(c(0,aux),1)) axis(2) text(d$mids, d$counts+0.5, paste(round(d$density*(max(x) - min(x))/6*100,2),"%", sep="")) # ----------------------- # RESULTADO # ----------------------- # valor mínimo = 4571 # valor máximo = 27772 # amplitude do intervalo = ( 27772 - 4571 ) ÷ 6 = 3866.833 Km2 # histograma1_frequencia_absoluta.png # histograma2_densidade_frequencia.png # tabela_frequencia.png |
Resultado
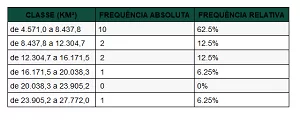
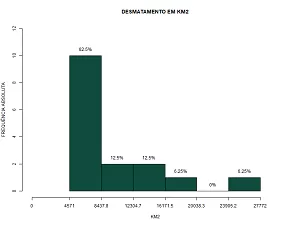
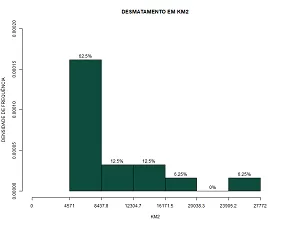
INFORMATIVO: Lembre-se no exemplo anterior a AMPLITUDES DOS INTERVALOS ERAM IGUAIS com tamanho 3866.833 km2.
ATENÇÃO: Caso o seu histograma tenha AMPLITUDES DIFERENTES a sua leitura poderá ser distorcida se forem utilizadas as frequências absolutas ou relativas.
Referências
Características Principais de um Histograma
Elementos de um Histograma
- Eixo horizontal (x): Representa os intervalos de valores (classes)
- Eixo vertical (y): Representa a frequência ou contagem de observações
- Barras: Mostram a frequência em cada intervalo
- Largura das barras: Representa a amplitude do intervalo
- Altura das barras: Representa a frequência no intervalo
Diferenças para Gráfico de Barras
- No histograma, as barras são adjacentes (não há espaço entre elas)
- As categorias no eixo x são intervalos numéricos contínuos
- Usado para dados quantitativos contínuos
- Mostra a distribuição e forma dos dados
