
A convergência para Zero na Regressão de Ridge
Analogamente a um sistema físico que busca equilíbrio, a Regressão de Ridge possui uma propriedade matemática fundamental de convergir os coeficientes para zero. Ademais, este comportamento é uma consequência direta da formulação de sua função objetivo, conforme documentado no scikit-learn.
Fundamentação Teórica da Convergência
Primordialmente, a Regressão de Ridge modifica o problema dos Mínimos Quadrados Ordinários através da adição de um termo de penalização. Conforme a documentação oficial, a função objetivo é expressa por:
\(\min_{w} ||X w – y||_2^2 + \alpha ||w||_2^2\)Certamente, o termo \(\alpha ||w||_2^2\) introduz uma penalização que cresce quadraticamente com a magnitude dos coeficientes. Similarmente a uma força restauradora, este termo puxa os coeficientes em direção à origem.
Análise do Comportamento Assintótico
Quando examinamos os limites matemáticos, observamos que:
- Para \(\alpha \to 0\): Recuperamos a solução dos Mínimos Quadrados Ordinários
- Para \(\alpha \to \infty\): Os coeficientes convergem necessariamente para zero
- O termo dominante na função objetivo torna-se \(\alpha ||w||_2^2\)
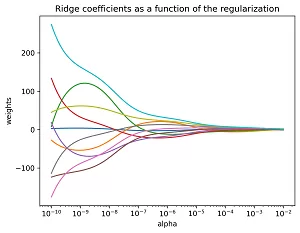
Exemplo Prático com Matriz de Hilbert
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 |
import numpy as np import matplotlib.pyplot as plt from sklearn import linear_model # X é a matriz de Hilbert 10x10 - notoriamente mal condicionada X = 1. / (np.arange(1, 11) + np.arange(0, 10)[:, np.newaxis]) y = np.ones(10) print("=" * 60) print("ANÁLISE DA CONVERGÊNCIA - MATRIZ DE HILBERT") print("=" * 60) print(f"Condicionamento da matriz: {np.linalg.cond(X):.2e}") print("Matriz extremamente mal condicionada - ideal para demonstrar Ridge") # Computar os caminhos n_alphas = 200 alphas = np.logspace(-10, -2, n_alphas) coefs = [] for a in alphas: ridge = linear_model.Ridge(alpha=a, fit_intercept=False) ridge.fit(X, y) coefs.append(ridge.coef_) # Análise quantitativa coefs_array = np.array(coefs) print(f"\nVariação dos coeficientes:") print(f"Alpha mínimo ({alphas[0]:.2e}): Norma L2 = {np.linalg.norm(coefs_array[0]):.2e}") print(f"Alpha máximo ({alphas[-1]:.2e}): Norma L2 = {np.linalg.norm(coefs_array[-1]):.2e}") # Mostrar resultados ax = plt.gca() ax.plot(alphas, coefs) ax.set_xscale('log') plt.xlabel('alpha') plt.ylabel('weights') plt.title('Ridge coefficients as a function of the regularization') plt.axis('tight') # Salvar a imagem com alta qualidade plt.savefig('ridge_coefficients.png', dpi=300, bbox_inches='tight') print("\nGráfico salvo como 'ridge_coefficients.png' com 300 DPI") plt.show() # 💡 ANÁLISE ADICIONAL print("\n" + "=" * 50) print("VERIFICAÇÃO MATEMÁTICA") print("=" * 50) # Verificação para alpha extremo alpha_extremo = 1e6 ridge_extremo = linear_model.Ridge(alpha=alpha_extremo, fit_intercept=False) ridge_extremo.fit(X, y) print(f"Para alpha = {alpha_extremo:.1e}:") print(f"Coeficientes: {ridge_extremo.coef_}") print(f"Próximos de zero? {np.allclose(ridge_extremo.coef_, 0, atol=1e-4)}") # Explicação matemática print(f"\nExplicação matemática:") print("Quando α → ∞, temos: (XᵀX + αI) ≈ αI") print("Portanto: w ≈ (αI)⁻¹Xᵀy = (1/α) * Xᵀy → 0") |
Interpretação do Mecanismo de Convergência
Inegavelmente, a convergência para zero decorre do fato de que, para valores muito grandes de alpha, o termo de penalização domina completamente a função objetivo. Afinal, minimizar \(\alpha ||w||_2^2\) requer necessariamente que \(||w||_2^2 \to 0\).
Benefícios Práticos Desta Convergência
Embora possa parecer contra-intuitivo, esta convergência oferece vantagens significativas:
- Estabilidade numérica: Previne coeficientes explosivos em problemas mal condicionados
- Controle de variância: Reduz a sensibilidade do modelo a pequenas variações nos dados
- Prevenção de overfitting: Coeficientes menores resultam em modelos mais conservadores
- Seleção implícita de features: Coeficientes próximos de zero indicam features menos importantes
Salvamento de Gráficos para Documentação
No código apresentado, a linha plt.savefig('ridge_coefficients.png', dpi=300, bbox_inches='tight') é fundamental para documentação. Analogamente a registrar resultados experimentais, salvar gráficos permite:
- Análise posterior dos resultados
- Inclusão em relatórios e publicações
- Comparação com outros experimentos
- Reprodutibilidade da pesquisa
O parâmetro dpi=300 garante alta resolução, enquanto bbox_inches='tight' remove bordas desnecessárias.
O Caso Específico da Matriz de Hilbert
No exemplo, a matriz de Hilbert é particularmente interessante porque é extremamente mal condicionada. Ocasionalmente, na regressão linear ordinária, os coeficientes podem atingir valores absurdamente grandes devido a instabilidade numérica.
Contudo, a Regressão de Ridge resolve este problema através da penalização L2. Similarmente a um amortecedor, ela controla as oscilações excessivas dos coeficientes.
Conclusão
Portanto, a convergência para zero não é um defeito da Regressão de Ridge, mas sim sua característica definidora. Analogamente a um sistema de controle que mantém variáveis dentro de limites seguros, a regularização L2 garante que os coeficientes permaneçam em magnitudes razoáveis.
Enfim, compreender este mecanismo é fundamental para aplicar corretamente técnicas de regularização em problemas práticos de machine learning. Inclusive, a capacidade de salvar e documentar visualizações é igualmente importante para o processo científico.
