
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
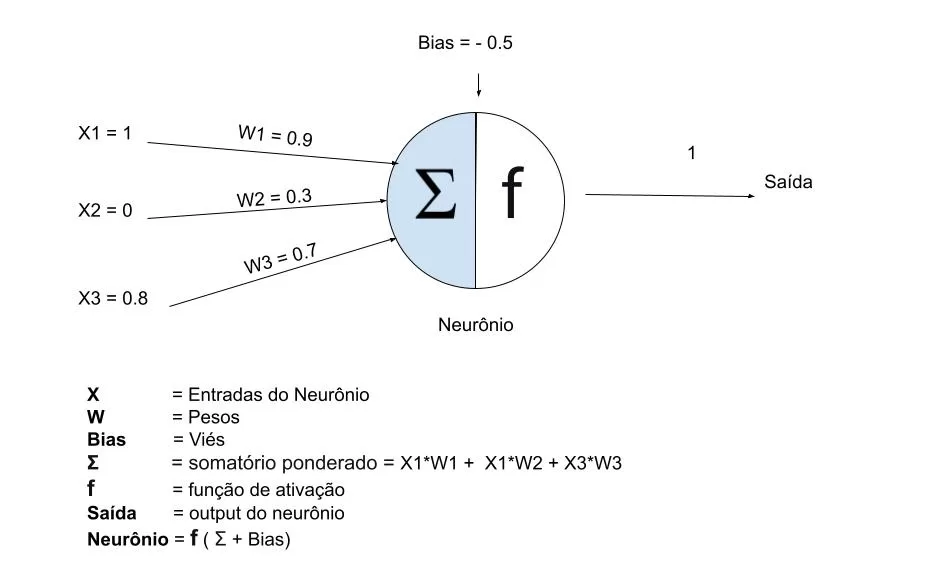
class Neuronio: def __init__(self): # x1, x2, x3 self.entradas = [1, 0, 0.8] # w1, w2, w3 self.pesos = [0.9, 0.3, 0.7] # bias self.bias = -0.5 def funcao_ativacao(self, soma): # Função degrau - simples "sim ou não" return 1 if soma >= 0 else 0 def calcular_saida(self): soma_ponderada = (self.entradas[0] * self.pesos[0] + self.entradas[1] * self.pesos[1] + self.entradas[2] * self.pesos[2] + self.bias) saida = self.funcao_ativacao(soma_ponderada) return saida, soma_ponderada # ✅ CORRETO: Criar uma INSTÂNCIA da classe neuronio = Neuronio() # Isso aqui é importante! saida, soma_ponderada = neuronio.calcular_saida() # Chamar na instância print("=== SEU ENTENDIMENTO CONFIRMADO ===") print(f"Entradas (x): {neuronio.entradas}") print(f"Pesos (w): {neuronio.pesos}") print(f"Bias: {neuronio.bias:.2f}") print(f"Média Ponderada: {neuronio.entradas[0]}*{neuronio.pesos[0]} + {neuronio.entradas[1]}*{neuronio.pesos[1]} + {neuronio.entradas[2]}*{neuronio.pesos[2]} + {neuronio.bias} = {soma_ponderada:.2f}") print(f"Saída: {saida}") """ ========== RESULTADO ========== === SEU ENTENDIMENTO CONFIRMADO === Entradas (x): [1, 0, 0.8] Pesos (w): [0.9, 0.3, 0.7] Bias: -0.50 Média Ponderada: 1*0.9 + 0*0.3 + 0.8*0.7 + -0.5 = 0.96 Saída: 1 """ |
A diferença de Perceptron e Neurônio Artificaial
-
- Apesar de frequentemente utilizados como sinônimos, perceptrons e neurônios artificiais representam conceitos com diferenças fundamentais na inteligência artificial. Embora ambos compartilhem a mesma inspiração biológica e estrutura básica – composta por entradas, pesos, bias e função de ativação – suas características distintivas definem aplicações e capacidades bastante específicas.
A Função de Ativação: O Divisor de Águas
-
- A diferença mais crucial reside na função de ativação empregada. O perceptron, em sua forma clássica, utiliza exclusivamente a função degrau, resultando em saídas estritamente binárias (0 ou 1). Esta característica o torna adequado para problemas de classificação linearmente separáveis, mas limita sua aplicação em cenários mais complexos. Em contraste, o neurônio artificial moderno pode incorporar diversas funções de ativação – como sigmoide, tanh, ReLU ou softmax – permitindo saídas contínuas e multivariadas que abrem portas para problemas de regressão e classificação não-linear.
Contexto Histórico e Evolutivo
-
- O perceptron emerge como pioneiro, desenvolvido por Frank Rosenblatt em 1957, representando o primeiro modelo concretizado de neurônio artificial. Sua simplicidade inicial, porém, revelou limitações que levaram a invernos da IA, particularmente na resolução de problemas não linearmente separáveis. O neurônio artificial, como conceito amplo, evoluiu para superar estas restrições, incorporando arquiteturas multicamadas e funções de ativação mais sofisticadas.
Aplicações e Capacidades
- Enquanto os perceptrons são tipicamente organizados em camadas únicas ou redes de poucas camadas, os neurônios artificiais contemporâneos formam a base das redes neurais profundas, com múltiplas camadas ocultas. Esta distinção arquitetural reflete-se diretamente na capacidade de aprendizado: o perceptron segue a regra do perceptron para ajuste de pesos, adequada para problemas lineares, enquanto os neurônios artificiais em redes profundas utilizam backpropagation com gradiente descendente, permitindo a modelagem de relações não-lineares complexas.
Conclusão
Em essência, a relação entre estes conceitos pode ser entendida como hierárquica: todo perceptron é um neurônio artificial, mas a recíproca não é verdadeira. O perceptron permanece como um caso específico dentro do espectro mais amplo de neurônios artificiais, cada um com suas vantagens e aplicações particulares no vasto ecossistema do aprendizado de máquina moderno.
Orientado a Objeto
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 |
import numpy as np class Neuronio: def __init__(self, entradas, pesos, bias=-0.5): if len(entradas) != len(pesos): raise ValueError( f"ERRO:\n" f" Número de Entradas : {len(entradas)}\n" f" Número de Pesos: {len(pesos)}\n" f" Número de Entradas e Pesos são DIFERENTES." ) self.entradas = np.array(entradas) self.pesos = np.array(pesos) self.bias = bias @property def somatorio(self): # Σ = (X1 * W1) + ... + (Xn * Wn) return np.dot(self.entradas, self.pesos) @property def total(self): # total = Σ + bias return self.somatorio + self.bias @property def funcao_ativacao(self): return 1 if self.total >= 0 else 0 @property def saida(self): return self.funcao_ativacao def __str__(self): """Representação em string do neurônio - para print()""" return ( f"NEURÔNIO ARTIFICIAL\n" f"├── Entradas: {list(self.entradas.tolist())}\n" f"├── Pesos: {list(self.pesos.tolist())}\n" f"├── Bias: {self.bias}\n" f"├── Somatório: {self.somatorio:.2f}\n" f"├── Total: {self.total:.2f}\n" f"└── Saída: {self.saida} {'Ativado' if self.saida == 1 else 'Desativado'}" ) def mostrar_calculo_detalhado(self): print("=" * 50) print("DETALHAMENTO") print("=" * 50) for i in range(len(self.entradas)): calc = self.entradas[i] * self.pesos[i] print(f"x{i+1} * w{i+1} = {self.entradas[i]} * {self.pesos[i]} = {calc:.2f}") print( f"NEURÔNIO ARTIFICIAL\n" f"├── Entradas: {list(self.entradas.tolist())}\n" f"├── Pesos: {list(self.pesos.tolist())}\n" f"├── Bias: {self.bias}\n" f"├── Somatório: {self.somatorio:.2f}\n" f"├── Total: {self.total:.2f}\n" f"└── Saída: {self.saida} {'Ativado' if self.saida == 1 else 'Desativado'}") # TESTE entradas = [1, 0, 0.8] pesos = [0.9, 0.3, 0.7] neuronio = Neuronio(entradas, pesos) print(neuronio) # Automaticamente chama __str__ neuronio.mostrar_calculo_detalhado() """ NEURÔNIO ARTIFICIAL ├── Entradas: [1.0, 0.0, 0.8] ├── Pesos: [0.9, 0.3, 0.7] ├── Bias: -0.5 ├── Somatório: 1.46 ├── Total: 0.96 └── Saída: 1 Ativado ================================================== DETALHAMENTO ================================================== x1 * w1 = 1.0 * 0.9 = 0.90 x2 * w2 = 0.0 * 0.3 = 0.00 x3 * w3 = 0.8 * 0.7 = 0.56 NEURÔNIO ARTIFICIAL ├── Entradas: [1.0, 0.0, 0.8] ├── Pesos: [0.9, 0.3, 0.7] ├── Bias: -0.5 ├── Somatório: 1.46 ├── Total: 0.96 └── Saída: 1 Ativado """ |