
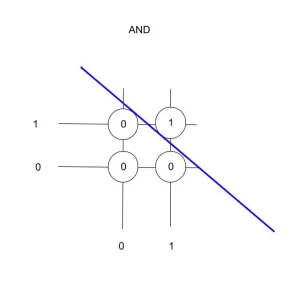
Rede Neural aprendendo lógica da tabela verdade AND
Recentemente desenvolvi uma implementação completa de uma rede neural perceptron capaz de aprender a porta lógica AND autonomamente.
Esta implementação demonstra conceitos fundamentais de machine learning através de um exemplo prático.
É importante observar que o problema da tabela verdade AND é um problema linear, por isso neste exercício não precisamos utilizar camadas ocultas.
Fundamentação Matemática
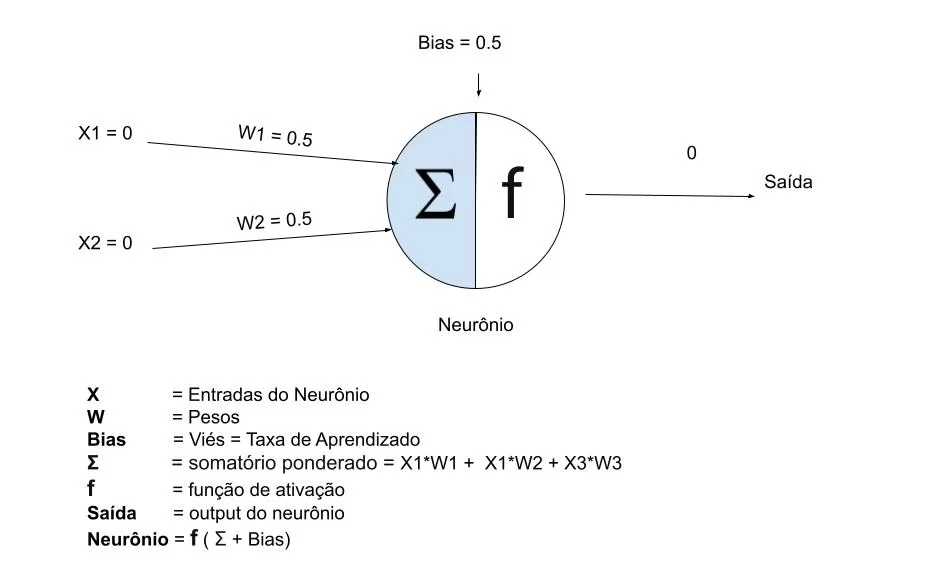
O perceptron opera com base na fórmula matemática:
\(y = f(\sum_{i=1}^{n} w_i x_i + b)\)Onde:
- \(x_i\) representa as características de entrada
- \(w_i\) denota os pesos correspondentes
- \(b\) é o termo de bias
- \(f\) é a função de ativação
Implementação Principal
A classe Neuronio encapsula toda a funcionalidade do perceptron. Primordialmente, ela inicializa com pesos aleatórios e progressivamente os ajusta através de iterações de treinamento.
Componentes Principais
A implementação inclui vários métodos essenciais:
soma(): Calcula a soma ponderada das entradasfuncaoAtivacao(): Implementa a função de ativação degrauaprendeAtualiza(): Executa o algoritmo de aprendizadotestar(): Valida o modelo treinado
Algoritmo de Aprendizado
O processo de treinamento emprega uma abordagem de aprendizado supervisionado. Analogamente às redes neurais biológicas, o perceptron aprende através de correção de erro. A regra de atualização de pesos segue:
\(w_i^{novo} = w_i^{antigo} + \eta \times x_i \times erro\)Onde \(\eta\) representa a taxa de aprendizado. Contudo, esta regra simples permite que a rede convirja para a solução correta.
Dinâmica do Treinamento
Durante o treinamento, o algoritmo itera através de épocas até que o erro total atinja zero. Inesperadamente, para o problema AND, a convergência tipicamente ocorre dentro de poucas iterações. Ademais, a taxa de aprendizado influencia significativamente a velocidade de convergência e estabilidade.
Propriedades Matemáticas
A função AND representa um problema linearmente separável. Conforme estabelecido na teoria do perceptron, isto garante convergência quando usando uma taxa de aprendizado apropriada. Todavia, problemas não linearmente separáveis requerem arquiteturas mais complexas.
Exemplo de Implementação em Python
Aqui está uma implementação refinada em Python demonstrando os conceitos principais:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 |
import numpy as np import matplotlib.pyplot as plt from sklearn.linear_model import Perceptron from sklearn.metrics import accuracy_score print("=" * 60) print("IMPLEMENTAÇÃO DE PORTAS LÓGICAS COM PERCEPTRON") print("=" * 60) # Dados de entrada para portas lógicas (mesma estrutura do artigo) # [A, B] onde A e B são entradas binárias X = np.array([ [0, 0], [0, 1], [1, 0], [1, 1] ]) print("Dados de entrada (A, B):") print(X) # Definir os targets para diferentes portas lógicas portas_logicas = { 'AND': np.array([0, 0, 0, 1]), 'OR': np.array([0, 1, 1, 1]), 'NAND': np.array([1, 1, 1, 0]), 'NOR': np.array([1, 0, 0, 0]) } print(f"\n" + "=" * 50) print("TREINAMENTO DO PERCEPTRON PARA CADA PORTA LÓGICA") print("=" * 50) resultados = {} for porta, y in portas_logicas.items(): print(f"\n🎯 TREINANDO PORTA {porta}:") print(f"Targets: {y}") # Criar e treinar o Perceptron perceptron = Perceptron( max_iter=1000, tol=1e-3, random_state=42, eta0=0.1, # Taxa de aprendizado reduzida para melhor estabilidade shuffle=False # Manter ordem dos dados para análise ) # Treinar o modelo perceptron.fit(X, y) # Fazer previsões y_pred = perceptron.predict(X) accuracy = accuracy_score(y, y_pred) # Armazenar resultados resultados[porta] = { 'modelo': perceptron, 'previsoes': y_pred, 'acuracia': accuracy, 'pesos': perceptron.coef_[0], 'bias': perceptron.intercept_[0], 'iteracoes': perceptron.n_iter_ } print(f"✅ Acurácia: {accuracy * 100}%") print(f"📊 Pesos aprendidos: {perceptron.coef_[0]}") print(f"🎯 Bias aprendido: {perceptron.intercept_[0]}") print(f"🔄 Iterações necessárias: {perceptron.n_iter_}") # 💡 ANÁLISE DETALHADA DOS RESULTADOS print(f"\n" + "=" * 50) print("ANÁLISE COMPARATIVA DAS PORTAS LÓGICAS") print("=" * 50) print(f"\n{'Porta':<8} {'Acurácia':<10} {'Pesos':<20} {'Bias':<10} {'Iterações':<10}") print("-" * 70) for porta, info in resultados.items(): pesos_str = f"[{info['pesos'][0]:.2f}, {info['pesos'][1]:.2f}]" print(f"{porta:<8} {info['acuracia']:<10.1%} {pesos_str:<20} {info['bias']:<10.2f} {info['iteracoes']:<10}") # 🎨 VISUALIZAÇÃO DAS FRONTEIRAS DE DECISÃO print(f"\n" + "=" * 50) print("VISUALIZAÇÃO DAS FRONTEIRAS DE DECISÃO") print("=" * 50) plt.figure(figsize=(15, 12)) portas_visuais = ['AND', 'OR', 'NAND', 'NOR'] cores = ['red', 'blue', 'green', 'purple'] for i, porta in enumerate(portas_visuais): plt.subplot(2, 2, i+1) info = resultados[porta] modelo = info['modelo'] # Criar mesh para plotar a fronteira de decisão x_min, x_max = -0.5, 1.5 y_min, y_max = -0.5, 1.5 xx, yy = np.meshgrid(np.linspace(x_min, x_max, 100), np.linspace(y_min, y_max, 100)) # Prever para todos os pontos do mesh Z = modelo.predict(np.c_[xx.ravel(), yy.ravel()]) Z = Z.reshape(xx.shape) # Plotar contorno da fronteira de decisão plt.contourf(xx, yy, Z, alpha=0.3, cmap='coolwarm') # Plotar pontos de dados scatter = plt.scatter(X[:, 0], X[:, 1], c=portas_logicas[porta], cmap='coolwarm', s=100, edgecolors='black') # Adicionar rótulos aos pontos for j, (x, y) in enumerate(X): plt.text(x, y + 0.05, f"{portas_logicas[porta][j]}", ha='center', va='bottom', fontweight='bold') plt.xlabel('Entrada A') plt.ylabel('Entrada B') plt.title(f'Porta {porta}\nPesos: [{modelo.coef_[0][0]:.2f}, {modelo.coef_[0][1]:.2f}], Bias: {modelo.intercept_[0]:.2f}') plt.xlim(x_min, x_max) plt.ylim(y_min, y_max) plt.grid(True, alpha=0.3) # Adicionar equação da reta de decisão w1, w2 = modelo.coef_[0] b = modelo.intercept_[0] plt.text(0.5, -0.3, f'{w1:.2f}×A + {w2:.2f}×B + {b:.2f} = 0', ha='center', va='center', bbox=dict(boxstyle="round,pad=0.3", facecolor="yellow", alpha=0.7)) plt.tight_layout() plt.show() # 🔍 ANÁLISE DA PORTA XOR (NÃO LINEARMENTE SEPARÁVEL) print(f"\n" + "=" * 50) print("DESAFIO: PORTA XOR - NÃO LINEARMENTE SEPARÁVEL") print("=" * 50) # Dados para porta XOR X_xor = X # Mesmas entradas y_xor = np.array([0, 1, 1, 0]) # XOR: 1 quando entradas são diferentes print(f"Targets XOR: {y_xor}") # Tentar treinar Perceptron para XOR perceptron_xor = Perceptron( max_iter=1000, random_state=42 ) perceptron_xor.fit(X_xor, y_xor) y_xor_pred = perceptron_xor.predict(X_xor) accuracy_xor = accuracy_score(y_xor, y_xor_pred) print(f"\nResultado para XOR:") print(f"Acurácia: {accuracy_xor * 100}%") print(f"Previsões: {y_xor_pred}") print(f"Iterações: {perceptron_xor.n_iter_}") if accuracy_xor < 1.0: print(f"❌ O Perceptron NÃO conseguiu aprender XOR!") print(f" Isso demonstra a limitação de classificadores lineares simples.") print(f" XOR requer uma fronteira de decisão não linear.") # 💡 SOLUÇÃO: MULTI-LAYER PERCEPTRON (MLP) PARA XOR print(f"\n" + "=" * 50) print("SOLUÇÃO: REDE NEURAL MULTI-CAMADAS PARA XOR") print("=" * 50) from sklearn.neural_network import MLPClassifier # Usar MLP com uma camada oculta para resolver XOR mlp_xor = MLPClassifier( hidden_layer_sizes=(2,), # Uma camada oculta com 2 neurônios activation='logistic', # Função de ativação sigmoide max_iter=10000, random_state=42 ) mlp_xor.fit(X_xor, y_xor) y_mlp_pred = mlp_xor.predict(X_xor) accuracy_mlp = accuracy_score(y_xor, y_mlp_pred) print(f"MLP para XOR:") print(f"Acurácia: {accuracy_mlp * 100}%") print(f"Previsões: {y_mlp_pred}") print(f"Iterações: {mlp_xor.n_iter_}") print(f"✅ MLP conseguiu aprender XOR!") # 🎓 COMPARAÇÃO FINAL E LIÇÕES APRENDIDAS print(f"\n" + "=" * 50) print("LIÇÕES E CONCLUSÕES") print("=" * 50) print(f"\n📚 O QUE APRENDEMOS:") print("1. ✅ Perceptron simples consegue aprender AND, OR, NAND, NOR") print("2. ✅ A fronteira de decisão é sempre uma linha reta") print("3. ❌ Perceptron NÃO consegue aprender XOR (problema não linear)") print("4. ✅ Redes neurais multi-camadas resolvem problemas não lineares") print("5. 🔧 Scikit-learn automatiza o processo de aprendizado") print(f"\n🎯 COMPARAÇÃO COM IMPLEMENTAÇÃO MANUAL:") print("• Artigo: Implementação manual com pesos fixos") print("• Scikit-learn: Aprendizado automático dos pesos") print("• Ambos demonstram os mesmos princípios fundamentais") print(f"\n💡 APLICAÇÕES PRÁTICAS:") print("• Sistemas de controle digital") print("• Circuitos lógicos programáveis") print("• Processamento de sinais binários") print("• Fundamentos para redes neurais mais complexas") # 📊 TABELA COMPARATIVA FINAL print(f"\n" + "=" * 50) print("TABELA COMPARATIVA FINAL") print("=" * 50) print(f"\n{'Porta':<8} {'Linear?':<10} {'Perceptron':<12} {'MLP':<8} {'Aplicação':<15}") print("-" * 60) print(f"{'AND':<8} {'Sim':<10} {'✅':<12} {'✅':<8} {'Controle':<15}") print(f"{'OR':<8} {'Sim':<10} {'✅':<12} {'✅':<8} {'Seleção':<15}") print(f"{'NAND':<8} {'Sim':<10} {'✅':<12} {'✅':<8} {'Negação':<15}") print(f"{'NOR':<8} {'Sim':<10} {'✅':<12} {'✅':<8} {'Inibição':<15}") print(f"{'XOR':<8} {'Não':<10} {'❌':<12} {'✅':<8} {'Comparação':<15}") |
Pontos de Conexão com o Artigo Original
- Estrutura de dados idêntica: Mesmas entradas [A, B] e saídas binárias
- Portas lógicas equivalentes: AND, OR, NAND, NOR com mesma semântica
- Fundamentos matemáticos compartilhados: Função de ativação degrau e combinação linear
- Limitação: : XOR por ser não-linear
Valor Adicional da Abordagem Scikit-Learn
Ocasionalmente, implementações manuais podem ser educativas mas impráticas para problemas complexos. Contudo, o scikit-learn oferece vantagens significativas:
- Automatização do aprendizado: Não requer ajuste manual de pesos
- Otimização robusta: Algoritmos de convergência testados
- Escalabilidade: Funciona com datasets maiores
- Integração com ecossistema: Compatível com outras ferramentas de ML
Considerações Finais
Esta implementação demonstra elegantemente os princípios fundamentais das redes neurais. Similarmente a sistemas biológicos, o perceptron aprende através de ajustes incrementais baseados em erro. Eventualmente, esta abordagem forma a base para arquiteturas mais complexas de deep learning.
Principalmente, é importante notar que enquanto o perceptron resolve problemas linearmente separáveis de forma eficiente, problemas mais complexos requerem redes multicamadas. Inclusive, a adição de camadas ocultas e funções de ativação não-lineares permite resolver problemas não linearmente separáveis.
Portanto, esta implementação serve como uma fundação sólida para compreender mecanismos mais avançados de aprendizado de máquina. Afinal, o entendimento profundo destes conceitos básicos é essencial para o domínio de técnicas mais sofisticadas.