Você já parou para pensar como um aplicativo de mapas encontra a melhor rota? Ou como um sistema organiza os horários de uma faculdade inteira? A resposta, muitas vezes, está nos Problemas de Satisfação de Restrições (CSPs). Eles formam uma área poderosa da Inteligência Artificial. A importância desses problemas reside na sua capacidade de modelar situações complexas do mundo real. Basicamente, um CSP busca uma solução que atenda a um conjunto de regras pré-definidas. Essa abordagem permite que máquinas realizem deliberações inteligentes de forma estruturada. Portanto, dominar esse conceito é o primeiro passo para criar sistemas autônomos e eficientes.
Modelando o Mundo Real com Restrições
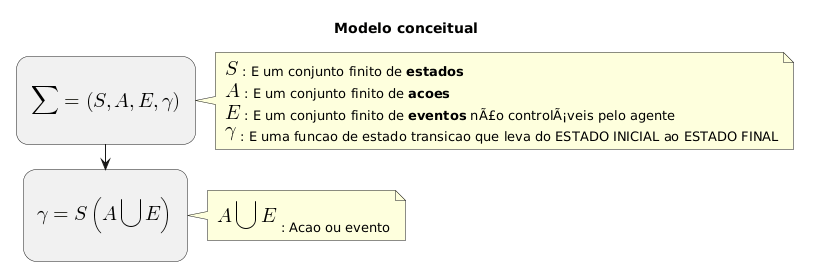
A modelagem de problemas através de CSPs começa com a identificação de três componentes fundamentais. Primeiro, definimos as variáveis, que são os elementos do problema que precisam de um valor. Em segundo lugar, estabelecemos o domínio para cada variável, ou seja, o conjunto de valores possíveis que ela pode assumir. Por fim, e mais crucial, temos as restrições, que são as regras que limitam as combinações de valores entre as variáveis. Essas regras ditam o que é permitido ou proibido em uma solução viável. As restrições podem ser de diversos tipos, como unárias (envolvem uma só variável) ou binárias (relacionam duas variáveis). Consequentemente, a arte de resolver um CSP está em encontrar uma atribuição de valores que respeite todas elas.
A Busca pela Solução: Objetivos e Algoritmos
O objetivo principal em um problema de satisfação é encontrar uma configuração que não viole nenhuma restrição. No entanto, muitos cenários exigem ir além da simples satisfação. Frequentemente, buscamos a melhor solução possível, introduzindo os objetivos de otimização. Por exemplo, podemos querer a rota mais curta ou o menor custo de produção. Para alcançar esses objetivos, a IA emprega diversos algoritmos de otimização. Um método clássico e passo-a-passo é o backtracking, que testa atribuições e retrocede ao encontrar um conflito. Algoritmos mais avançados, como a busca local (hill climbing) ou a propagação de restrições, aceleram essa busca. Eles podam o espaço de possibilidades, tornando a deliberação inteligente muito mais rápida e prática.
Na Prática: Um Exemplo de Agendamento de Provas
Vamos aplicar esses conceitos em um exemplo prático para solidificar o entendimento. Imagine que você precisa agendar as provas finais de três disciplinas: Matemática, Física e História. Temos, portanto, três variáveis (Mat, Fis, His). O domínio de cada uma são os dias disponíveis: segunda ou terça. As restrições são claras: Matemática e Física não podem ser no mesmo dia, pois muitos alunos cursam ambas. Além disso, História deve ser no mesmo dia que Física, pois os professores precisam se reunir.
1. Variáveis: Mat, Fis, His.
2. Domínios: {Segunda, Terça} para todas.
3. Restrições:
– Mat ≠ Fis (Matemática e Física em dias diferentes).
– His = Fis (História e Física no mesmo dia).
O algoritmo de busca precisa encontrar uma combinação que respeite essas regras. Ele pode começar atribuindo “Segunda” para Mat. Pela primeira regra, Fis não pode ser “Segunda”, então só pode ser “Terça”. Pela segunda regra, His deve ser igual a Fis, portanto também “Terça”. A solução encontrada é Mat=Segunda, Fis=Terça, His=Terça. Esse processo demonstra como a modelagem transforma um problema do mundo real em um formato que a IA pode resolver sistematicamente. Compreender esse fluxo é essencial para aplicar CSPs em áreas como logística, design e inteligência artificial em geral.